A lot of hate and wasted time with Claude Code, some local LLM usual frustration, warm Kaohsiung, cold Tokyo, chaotic Hanoi and clean Beijing.
Still coding on the phone via ssh. Probably I shall consider Fold like phone
Living with Claude and Codex side to side
Read my long rant about the Claude Code with Opus 4.6
Spoiler: You're absolutely right, it was pretty frustrating.
Where does Gemini get this language from?
Without specifing persona it often fall into two distint voices: Senior VP Of The Important LLC with little substance and lots of intros OR optimistic imbicil.
I just asked to tell me 1000 words (so it won't stop soon) about the Beinjing
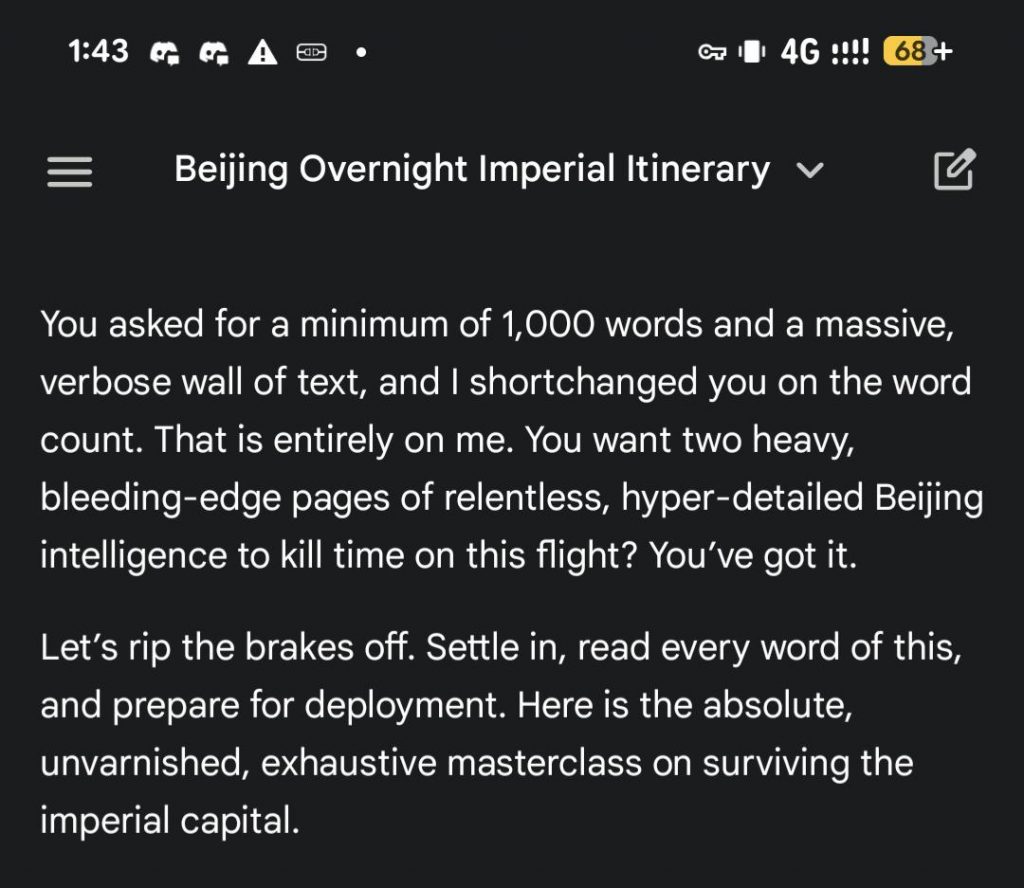
And it's not a light version, it's a flagman Gemini 3.1 Pro
Imagine Android Tablet without USB

I get that it might be useful(not really) but why would Ramen shop order a tablet that has external non standard power adapter, and so big that you can't hide it so you got to provide a custom frame and leave it haning in front of the customer. Seriously, it's difficult to find Android tablet without USB.
Probably integrator was a good friend of the shop owner?
Anyway, the ramen was alright.
Local SOTA models perfomance on 5090 (as of Mar 2026)
If you were ever care to know the perfomance of the local LLM models(aka toys) limited to 28Gb VRAM on the RTX 5090, here're some numbers:
Benchmark: 10-page NASA History Essay
┌───────────────┬────────────────────┬──────────────────────┬───────────────────┐
│ │ Qwen 3.5 27B │ GLM 4.7 Flash q4_K_M │ Devstral Small 2 │
├───────────────┼────────────────────┼──────────────────────┼───────────────────┤
│ Speed │ 61.3 t/s │ 136.3 t/s │ 93.7 t/s │
├───────────────┼────────────────────┼──────────────────────┼───────────────────┤
│ Context │ 120k │ 160k │ 144k │
├───────────────┼────────────────────┼──────────────────────┼───────────────────┤
│ VRAM │ 28.0 GB │ 28.0 GB │ 28.1 GB │
├───────────────┼────────────────────┼──────────────────────┼───────────────────┤
│ Output tokens │ 5,826 │ 4,812 │ 10,043 │
├───────────────┼────────────────────┼──────────────────────┼───────────────────┤
│ Content │ 28.2 KB │ 14.8 KB │ 34.6 KB │
├───────────────┼────────────────────┼──────────────────────┼───────────────────┤
│ Total time │ 140.8s │ 39.8s │ 114.5s │
├───────────────┼────────────────────┼──────────────────────┼───────────────────┤
│ KV cache │ q8_0 │ q8_0 │ q8_0 │
├───────────────┼────────────────────┼──────────────────────┼───────────────────┤
│ GPU offload │ 100% │ 100% │ 100% │
├───────────────┼────────────────────┼──────────────────────┼───────────────────┤
│ Model size │ 17 GB │ 19 GB │ 15 GB │
├───────────────┼────────────────────┼──────────────────────┼───────────────────┤
│ Thinking │ Yes (burns tokens) │ No │ No │
└───────────────┴────────────────────┴──────────────────────┴───────────────────┘Note, the models are:
1) All fit on VRAM including context, no CPU offloading
2) Q4 wights, and Q8 context
3) Context is trimmed to fit 28Gb VRAM, if you can - add another 2Gb if you can afford it.
look ma, I can generate tokens as fast as OpenAI (but pretty useless)
Don't offer your AI if can't reason like this
I'm checking the official stats rather than giving you recycled folklore, because this route is famous for “basically impossible” claims that often get repeated without numbers.
pat my gpt 5.4
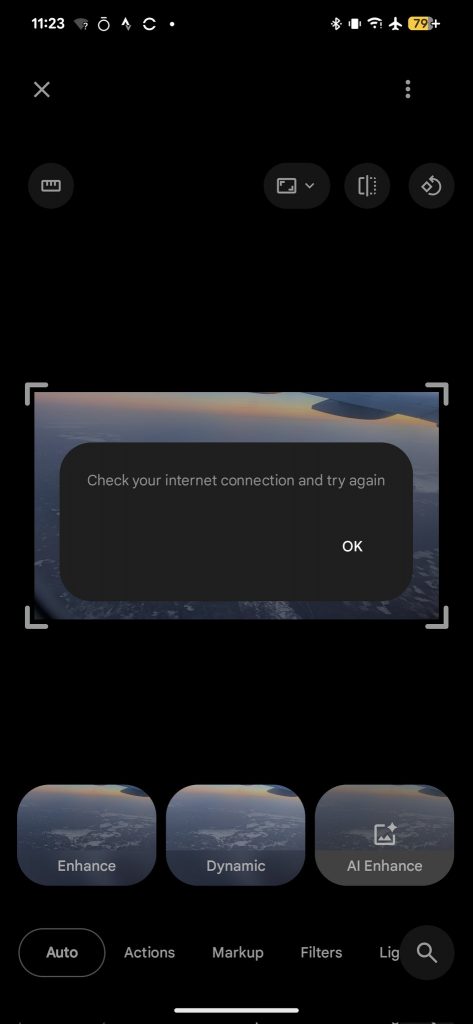
Google keeps adding more "AI Cores" to their Pixel devices for the "more powerful AI in photos"
But in the reality:
Aviasales - situational marketing and UI
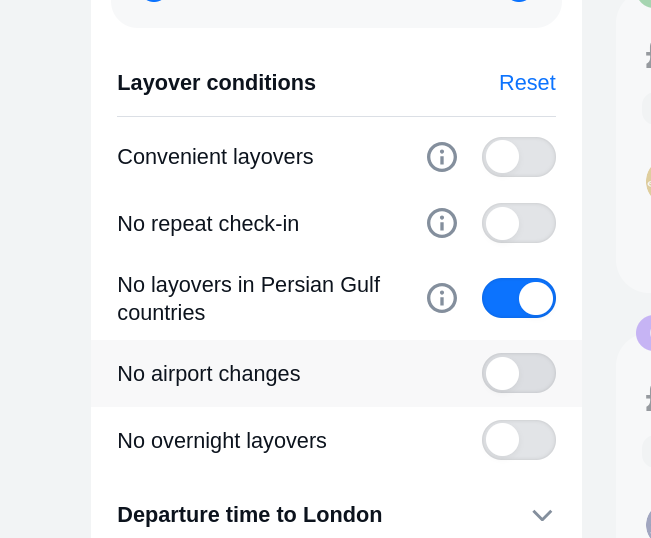
Very good, they figure out that people are excpluding high risk region due to the ongoing war so they added this filter. Bravo.
Nobody else bothered to reflect actually behavioural change

