
Even when one thinks in English, it doesn't guarantee fluency or that one will sound like a native speaker. To me, one of the most expressive ways to communicate is through the use of phrases and idioms, as they convey rich meanings in just a few words, somewhat acting as memes.
Since I got quite fed up with crypto, I decided to jump on the hype train and try to make use of democratized AI, particularly locally deployed LLMs and StableDiffusion.
Much like how I missed the Ethereum "smart contract" revolution, I soon realized I was late to the AI party. But I suppose it's all relative; for some, Kotlin is still a new language, and for others, crypto is synonymous with drugs and money laundering.
Introducing My New Project: PhrasesHub.com
This website is a personal solution to a problem I've encountered. They say if it solves at least your problem, you've already got one user.
Concept
PhrasesHub is a website about English idioms and phrases, aimed at helping advanced English learners improve their fluency.
While there are many similar websites, the key defferentiators are:
- It goes beyond dry definitions. For idioms, traditional dictionaries often fall short. Expressions can't be effectively used without context and examples.
- Examples are vital, especially for ambiguous phrases like "There's no place like home".
- Context is key to explain the phrases, so I added a page with stories heavily using idioms, giving readers real-life examples of the usage of the phrases.
- To reach a broader audience, each idiom (eventually) will have a page in different languages, making the site accessible even to those at an A2 level.
- Dare to say, the website logo stands out.
Traffic Volume
I'm well aware that google has 'quick answer' feature for expressions and idioms, but it turns out people are still get themselves to the relevant websites. Analysing public data / SEO rankings I concluded that it's worth work on this idea, at least for educational purposes, though clearly it won't be anything material from the commercial point of view. However, the skills I learn can open up more opportunities down the road.
Comparing it to theidioms.com, which has a strong SEO rank in different regions, only trailing behind major dictionaries like Cambridge or Collins.
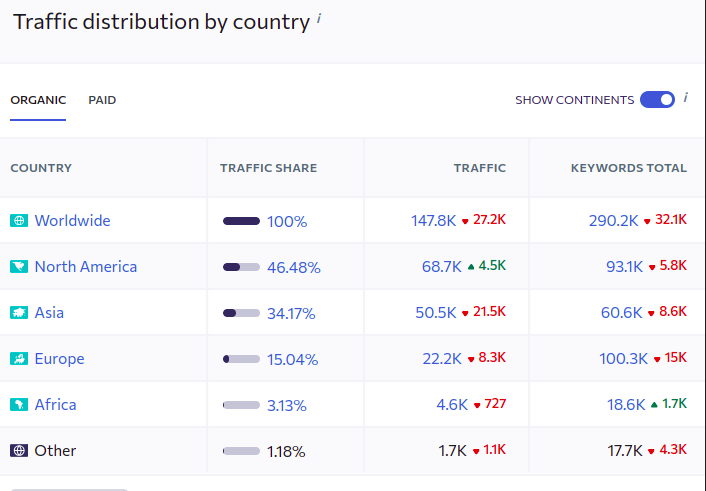
The organic is mostly from the immigrant countries, that rather confirms my guess about the users' profile
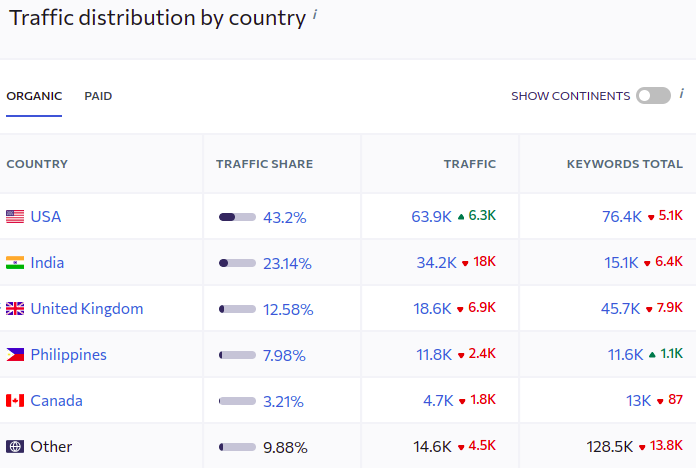
Without going in details, I believe that 'long tail SEO' would work great here as it'd be possible to channel down user's ask straight to the highly relevant page explain "bite the hand that feeds" in Portugese. "Build and they come" won't work so I'd need to invest into this to get the ball rolling (that feeling that I can put a link back to my website!).
Implementation

Website Engine
The website is built with TypeScript, Next.js, and TailwindCSS, using the tailwind-nextjs-starter-blog template by timlrx @ GitHub. It's a time-saver compared to my last experience with Next.js where I wrote a lot of boilerplate code.
However, it has its challenges. For instance, the 'contentlayer' library, used for managing the MDX pre-rendered content, kept crashing with OOM, even after allocating 10GB of RAM, due to its inability to handle 2k web pages efficiently. You read it right, 2k, not even 2M pages...
Content Generation - LLMs
The fun begins with content generation using LLMs. It was quite a learning curve. I started with text-generation-webui by oobabooga to understand local model management. I learned about different formats, context size, tokenisation, quantisation, LoRA and eventually found myself finetuning the models. This all was new to me and I stepped into unfamiliar territory, yet I believe I have reached a level of practical application of these tools.
When I heard 'prompt engineering' for the first time, it struck me as an ironic term. However, it's an actual thing. Generating something you want from a model is not particularly challenging, but ensuring it consistently responds in the desired format and the way you expect without hallusinations is quite complex problem.
Thinking of LLMs as of super advanced autocomplete AND "eventually-correct" database helps to develop the right mindset for the prompt engineering.
Content Extraction Process
To generate content, initial seeding of phrases/idioms came from ChatGPT-4, followed by a series of 10+ prompts serving different purposes in a pipeline. Each pipeline step is a script that runs prompts, sanitizes, and parses responses, maintaining consistency in outputs.
To generate content, one must initiate the right queries. I began by seeding phrases/idioms/expressions from ChatGPT-4 and public sources, following by generating of the segments for each page section using a combination of models—OpenAI's GPT-3.5, GPT-4, and various local models. Some outputs were composed into the inputs for another models(for instance examples -> scene description -> stable diffusion cover image).
In total, I crafted over 50 prompts(along with thousand variations), but only 15+ were stable enough to be used in production and they were utilised to create pages block by block. Each step in the pipeline involves a dedicated script responsible for executing prompts, sanitasing, and parsing responses. While overall process is not complex it actually can quickly become a mess if there is not string separation of concerns. I found that adhering to the principle "given the same inputs, produce the same outputs" is helpful in managing the numerous moving parts caused by LLMs' fantasies.
Some observations
- Running a local LLM is often not justifiable if no private information is involved. It can be more costly due to electricity cost, especially if inexpencive old GPUs don't deliver high throughput or not utilised 100% of the time. From the development point of view when using CPU-offloading with GGUF the throughput drops rapidly. As a result the wait time for the response might take like 5 minutes so experimentation become a real problem. I ended up running dozens of prompts through the script while capturing output to the file, so I could analyse the output quality in batches.
Even with a powerful desktop, 7B models without quantization produce only about 22 tokens/s. Meanwhile, a quantized GGUFed model Q5 for a 34B model with CPU offloading outputs only 3.5 tokens/s. - Writing pipelines in TypeScript is a hassle; the underlying Node standard library is quite elementary. This isn't news, as not much has changed since its inception, but it's still worth noting.
- GPT-4 seems to struggle with comparing idioms across languages, often resorting to direct translation as if it were the standard approach.
- The frontmatter and contentlayer, or both in combination, are exceedingly slow. It's frustrating that running the simplest frontend requires 10GB of RAM. Not to mention, Next.js launches its own daemons on top of the main application in development mode.
- OpenAI has made model training quite user-friendly. However, training local models is far from straightforward and can be challenging to perfect, particularly when experimenting with different source models that have varying system/input/output formats and numerous training parameters that affect behavior. Adding to the complexity, I had to adjust the hyperparameters during inference after each model training iteration.
I found myself using multiple LLMs simultaneously - ChatGPT-3/4, Idea's AI helper, GitHub's Co-pilot, and local LLMs, along with scripted pipelines using OpenAI API. It was a somewhat surreal experience because it felt like I was hypercharged, acting more as an Executor or Models Connector rather than an AI Supervisor.
Roughly, time used:
- Web stuff (refreshing Next.js/frontned knowledge, wrestling with Contentlayer, deployment, styles) – 15 hours
- Learning LLM basics (formats, parameters, deployments, inference, training) – 20 hours
- Crafting prompts (ensuring quality and consistency, token use optimizations) – 20 hours
- Scripting pipelines (mostly ETL around a bunch of JSONs & MDXs) – 10 hours
Let's see how it goes.
