

I have several post about the PronounceMe project experiments - automatic video and voice generator for English learners. If you missed previous posts please review #pronounceMe for more information about the project, ideas behind and some statistics. In this post I'd focus on the technical implementation with some diagrams and noticeable code snippets.
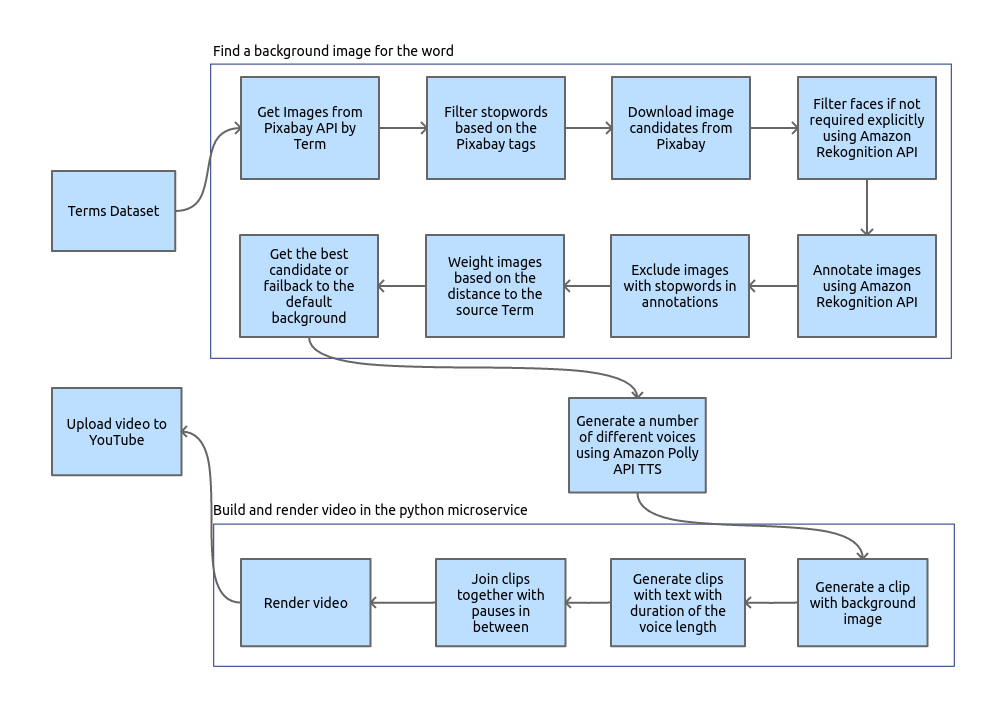
Service diagram
Essentially, the service consist number of the components:
- Terms Database - dataset of the words
- Voice generator - engine which generates human-alike voices
- Picture lookup service - huge part which is responsible for finding relevant background picture
- Video generator - renderer of the video which composes the clips and voices
- Youtube Uploader - implementation of the client Youtube API
- Management panel - very basic web-based admin panel allowing to observe current status, database and statictics
- Statistics extractor - a regular fetching some statistics data


The central focus of the service is a Term - one or few words which need to be pronounced. Service is built around the pipeline which takes the term and transforms it into the uploaded Youtube video.

Bear in mind this project is at the MVP stage. That means there are several compromises I have chosen to reduce Time To Market. It's never late to improve code if the project is useful.
Technologies used
I could say it uses most-of-the-buzzwords such as Computer Vision, Mesh API, Cloud Services, Docker, Microservices and it won't be a lie. But we always want to see more specifics:
Generator service:
- Kotlin - of course, there are no other candidates. Most of the engine is built on it
- http4k - webserver written in kotlin, for kotlin
- kotlinx-html - dsl for html. There is no javascript in the project as such
- kmongo - as a DAO layer for the db
- java-pixabay - for Pixabay API access, the original project has been abandoned, I had to fork it
Video generator and render
It's a microservice working in the separate container, communicating with the engine via HTTP
- python3 - because of moviepy
- moviepy - the best programmatic video generator; I found anything similar for JVM.
- imageio - for image manipulation
- cherrypy - apparently the easiest way to expose python function via http REST service
Infrastructure:
- jib - jvm docker image generator
- mongo - default database for experiments/MVP
- docker - as a runtime
- docker-compose - for container orchestration
- docker-machine - for provisioning
- make - as a frontend for the deployment commands
Cloud API and services:
- AWS Rekognition - cloud computer vision API. It allows to filterout pictures with faces(often they create a lot of noise) and image image labeling for choosing the best picture
- AWS Polly - TTS engine provided by Amazon. Previously I tried one from MS Azure but quality wasn't satisfying. Polly generates nearly perfect voice with different accents
- YouTube API - for video uploads and statistics collection
- AWS EC2 - for hosting
- PaperTrail - for logs from the docker containers
Challanges
Well, there were a lot of issues, mostly related to the external services
1) YouTube API has limitations - each call counts towards daily quota(which is 1M units). From my experience, it's only possible to upload about 50 videos a day. Although I'd like to upload way more than limit set that didn't bother me much since the process is automated
2) moviepy heavily leaks memory. From my experiments that after 10 rendered videos python process held about 2Gb of RAM. Since it's MVP I have chosen the simplest solution - just restart microservice. More precisely, to configure docker-swarm to kill it once it consumed too much memory. I believe it's a very practical decision for the given project stage.
3) To make the video stand out from others it has to have a relevant background picture for the term. If the user looks for the "how to pronounce tomato" it's more likely that video with tomato on the background would be chosen rather than one with grey colour. To find images I used Pixabay API(if you like service don't forget to donate them too!). For the obvious reasons often some irrelevant pictures are returned, so I had to filter irrelevant pictures using Amazon computer vision.
4) Imagemagik policies hurt. It's a great library but I found it tricky to configure since it has a configuration file where defaults are very tight. For example it's impossible to generate video into the /tmp folder by default. Thanks to docker it's very easy to build up the image with embedded configuration.
5) Apparently, docker-compose has changed the behaviour for the container limits so I had to downgrade configuration file from version 3.3 to 2.3
6) I wanted to keep MongoDB outside of the container on the host machine for my personal reasons. If you ever tried to do so you know it's not easy. The container ecosystem is pushing a user to use containers only. I ended up binding /var/lib/mongodb/mongod.sock from host to container and use jnr-unixsocket to make mongo to use unix socket instead of TCP
7) Youtube API documentation seems to be very convoluted, I had a hard time to understand how to go from the simple youtube upload to something like "create a playlist if need and then specify description along with tags and location of the video in different languages"
Enjoyable parts
This project is actually quite interesting to work on. It uses many external APIs, works with computer vision(a lot of fun with debugging!), etc
- kotlin is soo nice, as usual. Can't imagine myself using python which can expode after every single type or java where I would write a few books and still it's not that clean
- Writing web pages in kotlin with kotlinx-html is really fun. Just think - statically typed html templates!
- Amazon Rekognition works like a magic, I'd say in 90% it sees what I'd say about the picture. Prices are very competitive for my use case
- Sealed classes work really well for the statistics collection and voices description
- kmongo allows to express db queries via staticly typed DSL. As most ORM it fails on the complex constructions but perfomance of the DB communication is never consern for this project
- java-pixabay library has been outdated, I made a few PRs but author had not got back to me. For that reason I continued to work on my fork - ruXlab/pixabay-java-api
Code snippets
I'd like to highlight some code used in PronounceMe service
kotlinx-html templates
private inline fun <reified T : Any> BODY.dumpListAsTable(
list: List<T>, fields: Collection<KProperty1<T, *>> = T::class.memberProperties
) = table("table table-striped table-hover") {
thead {
tr {
for (field in fields)
th { +field.name }
}
}
tbody {
for (row in list) {
tr {
for (field in fields)
td { +field.get(row).toString() }
}
}
}
}
private fun youtubePlaylists(req: Request): Response = pageTemplate("Youtube playlists", autoreload = false) {
dumpListAsTable(
youtubeClient.getPlaylists(),
listOf(YoutubePlaylist::id, YoutubePlaylist::title, YoutubePlaylist::itemsCount, YoutubePlaylist::description)
)
. . . .
}
Outputs:

Navbar and html body
body {
nav("navbar navbar-expand-md navbar-dark bg-dark fixed-top") {
div("collapse navbar-collapse") {
ul("navbar-nav mr-auto") {
WebApp.webRoutes.filter { it.verb == Method.GET }.forEach {
li("nav-item") {
a(it.url, classes = "nav-link") {
+it.description
}
}
}
}
ul("navbar-nav mr-auto") {
li("nav-item") {
if (PronounceApp.isRunning.get()) {
h2 {
span("badge badge-danger badge-secondary") { +"Generator is running" }
}
} else {
form(action = "/forcestart", method = FormMethod.post, classes = "form-inline") {
button(classes = "btn btn-success", type = ButtonType.submit) { +"Force start" }
}
}
}
li("nav-item") {
a("https://papertrailapp.com/groups/XXXXXXX/events", "_blank", "nav-link button") {
+"logs"
}
}
}
}
}
main {
h1 { +title }
builder(this@body)
}
}
Result looks like:


Decent design for the private admin panel to be used every once in a few months by a single person, isn't it? :)
Server and routes
Handlers are defined as a list of routes with URL and handler function as expected in http4k
val webRoutes = listOf(
Route(GET, "/ping", "Ping it") { req -> Response(OK).body("pong") },
Route(GET, "/stat", "Some stats", this::stat),
Route(GET, "/events", "Recent events", this::recentEvents),
Route(GET, "/", "All urls available", this::root),
Route(GET, "/config", "Runtime config", this::config),
Route(GET, "/stat_channel", "Channel statistics", this::channelStat),
Route(GET, "/youtube_playlist", "YT playlists", this::youtubePlaylists),
Route(POST, "/forcestart", "Force start", this::forceStart),
Route(POST, "/createplaylist", "Create playlist", this::youtubePlaylistCreate)
)
The webserver itself is literally 3 lines of code
routes(*webRoutes.map { it.url bind it.verb to it.handler }.toTypedArray())
.asServer(SunHttp(port))
.start()
The heart of the image lookup component:
fun findImageForWordWithCandidates(
word: String,
category: Category?,
stopList: List<String>,
mandatoryList: List<String>? = null,
allowFaces: Boolean = false,
pixabyPage: Int = 1
): ImagesWithCandidates? {
val stopList = stopList.mapTo(HashSet(), String::toLowerCase)
val mandatoryList = mandatoryList?.mapTo(HashSet(), String::toLowerCase)
val allImages = imageLookup.searchPixabay(word, category, pixabyPage)
?.shuffled()
?.also { log.info("findImageForWord: got {} images for {}", it.size, word) }
?.mapNotNull {
// fetch pictures locally
runCatching {
ImageRuntimeInfo(it.largeImageURL, URL(it.largeImageURL).asCachedFile("pixaby-${it.id}-large"), pixaby = it)
}
.onFailure { log.warn("findImageForWord: during image saving", it) }
.getOrNull()
}
val images = allImages
// filter pics with faces if necessary
?.let { if (allowFaces) it else withoutFaces(word, it) }
?.also { log.info("findImageForWord: got ${it.size} pics after face filtering") }
// image labelling
?.let { findLabels(word, it) }
// exclude stop list words
?.filterNot { it.normalizedLabels.any { it in stopList } }
// exclude images without mandatory words
?.filter {
if (mandatoryList == null) true
else it.normalizedLabels.any { it in mandatoryList }
}
?.also { log.info("findImageForWord: got ${it.size} pics after filtering by label") }
?: return null
if (images.isEmpty()) {
log.warn("findImageForWord: No eligible images were found for {}", word)
return null
}
val sortedImagesByConfidence = images
.map {
// find the best matches by original word
val labelWithWord = it.labels
.sortedByDescending { it.confidence }
.firstOrNull { it.name.contains(word, ignoreCase = true) }
it to (labelWithWord?.confidence ?: -1.0F)
}
log.debug("findImageForWord: ${sortedImagesByConfidence.size} candidates for $word: \n{}",
sortedImagesByConfidence.joinToString("\n") { " - ${it.first} with ${it.second} confidence" })
val firstBestMatch = sortedImagesByConfidence
.firstOrNull { it.second > 0.0F } // return first by confidence
?.first
log.info("findImageForWord: best match for {} by label in word - {}",
word, firstBestMatch)
if (firstBestMatch != null)
return ImagesWithCandidates(firstBestMatch, allImages)
// we don't have best extact match by word in labels
val firstMatchByConfidence = sortedImagesByConfidence.firstOrNull()
log.info("findImageForWord: good match by confidence for {} - {}",
word, firstMatchByConfidence)
return ImagesWithCandidates(firstMatchByConfidence?.first, allImages)
}
Clips compose
Pardon me for my python
for idx, _ in enumerate(voice_title_clips):
prevoice_clip = CompositeVideoClip([static, voice_title_clips[idx]], size=screensize)
prevoice_clip.duration = pre_voice_pause
postvoice_clip = prevoice_clip.set_duration(post_voice_pause)
voice_title_clips[idx] = CompositeVideoClip([static, voice_title_clips[idx]], size=screensize)
voice_title_clips[idx].duration = voice_clips[idx].duration * voice_repeats + voice_repeats_pause_times * voice_clips[idx].duration
silence_clip = silence.set_duration(voice_clips[idx].duration * voice_repeats_pause_times)
voice_title_clips[idx].audio = concatenate_audioclips(intersperse([voice_clips[idx]] * voice_repeats, silence_clip))
clips = [prevoice_clip, voice_title_clips[idx], postvoice_clip, static.set_duration(pause_between)]
voice_title_clips[idx] = concatenate_videoclips(clips, padding=-1, method="compose")
What is next
Subscribe for the blog to see where this project goes. Breaking news is awaiting!
Checkout more project updates from posts grouped by #pronounceMe hashtag
